如何快速学习 C 语言?
大家好,我是小康,今天我们来聊下如何学习 C 语言。
C 语言,强大而灵活,是许多现代编程语言的基石。本文将带你快速了解 C语言 的基础知识,无论你是编程新手还是希望回顾基础,这里都有你需要的。
初学者在开始学习 C 语言的时候,往往不知道怎样高效的学习这门课,网上很多人都会推荐去看各种 C 语言书籍,我觉得没必要去看那么多,贪多嚼不烂!为了让更多初学的朋友快速入门 C 语言,我这里将 C 的各个知识点进行了汇总,并附有代码示例,以便大家理解,掌握这些就可以啦。如果你时间比较充足,可以看丹尼斯·里奇的《C程序设计语言》 这本书,再搭配浙大翁恺的 C 语言课程:C语言程序设计 浙江大学:翁恺_哔哩哔哩_bilibili
最佳的学习方法就是:根据我的知识点来看丹尼斯·里奇的《C程序设计语言》,再加上翁恺的 C 语言课程,搭配学习,效果最好。如果你认为自己自学能力很好或者时间有限,那么完全不需要看视频,本篇文章已经囊括了全部的知识点。
废话不多说了,直接带你快速入门 C 语言编程。
基础语法
1.标识符和关键字
标识符用于变量、函数的名称。规则:由字母、数字、下划线组成,但不以数字开头。
关键字是 C 语言中已定义的特殊单词,如 int、return 等。
1 | 示例: |
2.变量和常量
变量是可以改变值的标识符。
常量是一旦定义,其值不可改变的标识符。常量使用 const来定义
1 | 示例: |
3.运算符和表达式
在 C 语言中,运算符是用于执行特定数学和逻辑计算的符号。运算符可以根据它们的功能和操作数的数量被分为几个不同的类别。
算术运算符
这些运算符用于执行基本的数学计算。
1 | + 加法 |
关系运算符
关系运算符用于比较两个值之间的大小关系。
1 | == 等于 |
逻辑运算符
逻辑运算符用于连接多个条件(布尔值)。
1 | && 逻辑与 |
赋值运算符
赋值运算符用于将值分配给变量。
1 | = 简单赋值 |
位运算符
位运算符对整数的二进制表示进行操作。
1 | & 位与 |
递增和递减运算符
这些运算符用于增加或减少变量的值。此类运算符都只作用于一个操作数,因此也被称之为一元运算符
1 | ++ 递增运算符 |
条件运算符
C 语言提供了一个三元运算符用于基于条件选择两个值之一。
1 | ? : 条件运算符 |
下面是一些使用这些运算符的简单示例:
1 | int a = 5, b = 3; |
表达式是运算符和操作数组合成的序列。
1 | 示例: |
4.语句
C语言中的语句是构成程序的基本单位,用于表达特定的操作或逻辑。它们可以控制程序的流程、执行计算、调用函数等。语句以分号(;)结束,形成了程序的执行步骤。
C 语言的语句可以分为以下几类:
表达式语句:
最常见的语句,执行一个操作,如赋值、函数调用等,并以分号结束。
1 | a = b + c; |
复合语句(块)
由花括号{}包围的一系列语句和声明,允许将多个语句视为单个语句序列。
1 | { |
条件语句
根据表达式的真假来执行不同的代码块。
if语句:是最基本的条件语句,根据条件的真假来执行相应的代码块。
1
2
3
4
5if (condition) {
// 条件为真时执行
} else {
// 条件为假时执行
}switch语句:根据表达式的值选择多个代码块之一执行。
1
2
3
4
5
6
7
8
9
10switch(expression) {
case constant1:
// 表达式等于 constant1 时执行
break;
case constant2:
// 表达式等于 constant2 时执行
break;
default:
// 无匹配时执行
}
循环语句
重复执行一段代码直到给定的条件不满足。
while循环:先判断条件,条件满足则执行循环体。
1
2
3while (condition) {
// 条件为真时执行
}do-while循环:先执行一次循环体,然后判断条件。
1 | do { |
- for循环:在循环开始时初始化变量,然后判断条件,最后在每次循环结束时执行更新表达式。
1 | for (initialization; condition; increment) { |
跳转语句
提供了改变代码执行顺序的能力。
- break语句:用于立即退出最近的
switch或循环(while、do-while、for)语句。1
2
3
4for (int i = 0; i < 10; i++) {
if (i == 5)
break; // 当 i 等于5时退出循环
} - continue语句:跳过当前循环的剩余部分,并继续下一次循环的执行(仅适用于
while、do-while、for循环)。1
2
3for (int i = 0; i < 10; i++) {
if (i == 5) continue; // 当i等于5时,跳过当前循环的剩余部分
} goto语句:将控制转移到程序中标记的位置。尽管存在,但建议避免使用goto,因为它使得程序的流程变得难以追踪和理解。1
2
3
4label:
printf("This is a label.");
goto label;
数据类型
数据类型的一个常见用途就是:定义变量。常见的数据类型可以大致分为以下几个类别:
1.基本类型
整型:
整数类型用于存储整数值,可以是有符号的(可以表示负数)或无符号的(仅表示非负数)。其中 int 是最常用的整数类型。为了适应不同的精度需求和内存大小限制,C语言提供了几种不同大小的整数类型。
有符号整型:
- short int 或简写为short,用于存储较小范围的整数。它至少占用16位(2个字节)的存储空间。
- int 是最基本的整数类型,用于存储标准整数。在大多数现代编译器和平台上,它占用32位(4个字节)。
- long int 或简写为 long,用于存储比int更大范围的整数。它至少占用32位,但在一些平台上可能会占用64位(8个字节)。
- long long int 或简写为 long long,是C99标准引入的,用于提供更大范围的整数存储。它保证至少占用64位(8个字节)。
示例:
1 | int a = 5; // 定义一个整形变量,初始值为5 |
无符号整型:
unsigned short int 或简写为 unsigned short,专门用于存储较小范围的正整数或零。这种类型至少占用16位(2个字节)的存储空间。
unsigned int 是用于存储标准大小的非负整数的基本类型。在大多数现代编译器和平台上,它占用32位(4个字节)。
unsigned long int 或简写为 unsigned long,用于存储大范围的非负整数。这种类型至少占用32位,在其他平台上可能占用64位(8个字节)
unsigned long long int 或简写为 unsigned long long,是为了在需要非常大范围的正整数时使用的。按照C99标准规定,它至少占用64位(8个字节)。
示例:
1 | unsigned int x = 150; |
浮点型:
浮点类型用于存储实数(小数点数字),包括 float 和 double。
示例:
1 | float f = 5.25f; |
浮点型使用场景:float 和 double:用于需要表示小数的场景,如科学计算、金融计算等。float 提供了足够的精度,适合大多数应用,而 double 提供了更高的精度,适用于需要非常精确的计算结果的场景。
布尔类型:
布尔类型 bool 用于表示真(true)或假(false)。
示例:
1 | bool flag = true; |
布尔类型使用场景:bool 类型一般用于逻辑判断,表示条件是否满足。常用于控制语句(如if、while)的条件表达式,或表示函数返回的成功、失败状态。
枚举类型:
枚举(enum)允许定义一组命名的整数常量。使用关键字enum定义枚举类型变量。
示例:
1 | enum day {sun, mon, tue, wed, thu, fri, sat}; |
枚举类型使用场景:
枚举类型 enum 用于定义一组命名的整数常量,使程序更易于阅读和维护。常用于表示状态、选项、配置等固定的集合。
2.复合类型:
结构体
结构体(struct)允许将多个不同类型的数据项组合成一个类型。使用关键字struct定义结构体。
示例:
1 | // 定义 Person 结构体 |
结构体类型使用场景:用于组合不同类型的数据项,表示具有结构的数据。
表示实体或对象:用于封装和表示具有多个属性的复杂实体,如人、书籍、产品等。
数据记录:组织和管理具有多个相关字段的数据记录,适用于数据库记录、日志条目等。
网络编程:构造和解析网络协议的数据包,适用于客户端和服务器之间的通信。
创建复杂的数据结构:作为链表、树、图等复杂数据结构的基本构建块,通过指针连接结构体实现。
联合体
联合体(union)在 C 语言中是一个用于优化内存使用的特殊数据类型,允许在同一内存位置存储不同的数据类型,但任一时刻只能使用其中一个成员。联合体变量使用关键字union 来定义。
示例:
1 | union Data { |
联合体类型使用场景:
节省内存:当程序中的变量可能代表不同类型的数据,但不会同时使用时,联合体能有效减少内存占用。
底层编程:在需要直接与硬件交互,或需要精确控制数据如何存储和解读时,联合体提供了直接访问内存表示的能力。
网络通信:用于根据不同的协议或消息类型解析同一段网络数据。
类型转换:允许以一种数据类型写入联合体,然后以另一种类型读取,实现不同类型之间的快速转换。
3.派生类型:
数组
数组是一种派生类型,它允许存储固定数量的同类型元素。当然,类型可以是多种,整形,浮点型,结构体等类型。在内存中,数组的元素按顺序紧密排列。数组的使用使得数据管理更加方便,尤其是当你需要处理大量同质数据时。
同质数据:具有相同数据类型的元素或值
示例:
1 | // 定义 |
数组的索引从0开始,numbers[0]表示数组中的第一个元素。
指针
指针是存储另一个变量地址的变量。指针在C语言中非常重要,它提供了直接访问内存的能力,使得程序可以通过地址来操作变量。
声明和使用指针:
1 | int var = 10; |
通过指针访问值:
1 | printf("Value of var: %d\n", *ptr); // 使用解引用操作符*来访问指针指向的值 |
数组
上面有提到过数组的概念,接下来让我们来详细讲解下数组:
数组是一种存储固定数量同类型元素的线性集合。在C语言中,这意味着如果你有一组相同类型的数据要存储,比如一周内每天的温度,那数组就是你的首选。
声明与初始化
声明数组的语法相当直观。比如,你想存储5个整数,可以这样声明:
1 | int days[len]; |
这里,int表明了数组中元素的类型,days是数组的名称,而[len]则指定了数组可以存储元素的个数,len 必须是数值常量。
初始化数组可以在声明的同时进行,确保数组中的每个元素都有一个明确的起始值:
1 | int days[5] = {1, 2, 3, 4, 5}; |
如果数组的大小在初始化时已知,你甚至可以省略大小声明:
1 | int days[] = {1, 2, 3, 4, 5}; |
访问与遍历
数组的元素可以通过索引(或下标)进行访问,索引从0开始,这意味着在上面的 days 数组中,第一个元素是days[0],最后一个元素是days[4]。
遍历数组,即访问数组中的每个元素,通常使用循环结构,如for循环:
1 | for(int i = 0; i < 5; i++) { |
多维数组
多维数组是一种直接在类型声明时定义多个维度的数组。它们通常用于存储具有多个维度的数据,如矩阵或数据表。
定义和初始化
多维数组的定义遵循这样的格式:类型 名称[维度1大小][维度2大小]…[维度N大小];
1 | int matrix[2][3] = { |
这定义了一个2x3的整型矩阵,并进行了初始化。
访问元素
访问多维数组的元素需要提供每一个维度的索引:数组名[索引1][索引2]…[索引N];
1 | int value = matrix[1][2]; // 访问第二行第三列的元素 |
动态数组
动态数组提供了一种在运行时确定数组大小的能力,通过动态内存分配函数来实现。
动态一维数组:
动态一维数组通常通过指针和 malloc 或 calloc 函数创建:
malloc 分配的内存是未初始化的,而 calloc 会将内存初始化为零。
1 | int *arr = (int*)malloc(10 * sizeof(int)); // 分配10个整数的空间 |
动态多维数组:
动态多维数组的创建稍微复杂,因为需要为每个维度分别进行内存分配:
1 | int **matrix = (int**)malloc(2 * sizeof(int*)); // 创建2个指针的数组,对应2行 |
使用完动态数组后,必须手动释放其内存以避免内存泄漏:
动态一维数组内存的释放:
1 | free(arr) |
动态多维数组内存的释放:
1 | for(int i = 0; i < 2; i++) { |
数组与函数
在 C 语言中,数组可以作为参数传递给函数。不过,由于数组在传递时会退化为指向其首元素的指针,我们需要另外传递数组的大小:
1 | int array[10] = {1,2,3,4,5,6,7,8,9,10}; |
数组使用场景:
- 固定大小集合:适用于存储已知数量的数据元素。
- 顺序访问和高效索引:数组元素存储在连续的内存地址中,可以通过索引快速访问。
- 多维数据表示:可以方便地表示多维数据结构,如二维数组表示矩阵。
指针
在 C 语言中,指针是一种特殊的变量类型,它的值是内存中另一个变量的地址。指针提供了一种方式来间接访问和操作内存中的数据。
可以把指针想象成一个指向内存中某个位置的箭头。每个变量都占用内存中的一定空间,指针的作用就是记录那个空间的起始地址。
定义指针
指针的定义需要指定指针类型,它表明了指针所指向的数据的类型。定义指针的一般形式是:
1 | type* pointerName; |
其中 type 是指针所指向的数据的类型,*表示这是一个指针变量,pointerName 是指针变量的名称。
示例:
1 | int* ptr; // 定义一个指向int类型数据的指针 |
这个声明创建了一个名为ptr的指针,它可以指向int类型的数据。开始时,ptr未被初始化,它可能包含任意值(即任意地址)。在使用指针之前,通常会将其初始化为某个变量的地址,或者通过动态内存分配函数分配的内存块的地址。
指针的初始化
指针可以通过使用地址运算符 & 来获取变量的地址进行初始化:
1 | int var = 10; |
或者,指针也可以被初始化为动态分配的内存地址:
1 | int* ptr = (int*)malloc(sizeof(int)); // ptr指向一块新分配的int大小的内存 |
使用指针
解引用(Dereferencing)
通过解引用操作*,可以访问或修改指针所指向的内存位置中存储的数据。
1 | *ptr = 20; // 修改ptr所指向的内存中的值为20 |
指针运算
指针的真正强大之处在于它能进行算术运算,这使得通过指针遍历数组和访问数据变得非常高效。
- 递增(++):指针递增,其值增加了指向类型的大小(如int是4字节)。
- 递减(–):与递增相反,指针递减会减去指向类型的大小。
- 指针的加减:可以将指针与整数相加或相减,改变其指向。
指针递增(++)
1 | int arr[] = {10, 20}; |
指针递减(–)
1 | ptr--; // 回到arr[0] |
指针的加减
1 | ptr += 1; // 移动到arr[1] |
指针与数组
数组名在表达式中会被当作指向其首元素的指针。这意味着数组和指针在很多情况下可以互换使用。
1 | int arr[5] = {1, 2, 3, 4, 5}; |
指针与函数
函数参数为指针,通过传递指针给函数,可以让函数直接修改变量的值,而不是在副本上操作。
1 | void addTen(int *p) { |
返回指针的函数
函数也可以返回指针,但要确保指针指向的是静态内存或者是动态分配的内存,避免悬挂指针。
1 | // 返回静态内存地址 |
避免悬挂指针:
悬挂指针是指向已经释放或无效内存的指针。如果函数返回了指向局部非静态变量的指针,就会导致悬挂指针的问题,因为局部变量的内存在函数返回后不再有效。
1 | int* getLocalValue() { |
这是错误的做法,因为 value 是局部变量,在函数结束时被销毁,返回的指针指向一个已经不存在的内存位置。
函数指针
函数指针存储了函数的地址,可以用来动态调用函数。
1 | // 函数原型 |
指针数组与函数
指针数组可以用来存储函数指针,实现函数的动态调用。
1 | // 定义两个简单的函数 |
这个示例中,funcPtrs是一个存储函数指针的数组。通过指定索引,我们可以动态地调用hello或world函数。
多级指针
多级指针,例如二级指针,是指针的指针。它们在处理多维数组、动态分配的多维数据结构等场景中非常有用。
1 | int var = 5; |
指针使用场景:
- 动态内存管理:配合malloc、realloc、calloc等函数,实现运行时的内存分配和释放。
- 函数参数传递:允许函数通过指针参数修改调用者中的变量值。
- 数组和字符串操作:通过指针算术运算灵活地遍历和操作数组和字符串。
- 构建数据结构:是实现链表、树、图等复杂数据结构的基础。
字符串
在 C 语言中,字符串是以字符数组的形式存在的,以空字符 \0(ASCII码为0的字符)结尾。这意味着,当 C 语言处理字符串时,它会一直处理直到遇到这个空字符。理解这一点对于正确操作 C 语言中的字符串至关重要。
声明和初始化字符串
在 C 语言中,可以使用字符数组来声明和初始化字符串:
1 | char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'}; |
更简单的方式是使用字符串字面量,编译器会自动在字符串末尾加上\0:
1 | char greeting[] = "Hello"; |
字符串除了使用字符数组来表示还可以用字符指针。
1 | char *greeting = "Hello"; |
字符串的输入和输出
使用 printf 函数输出字符串,使用%s格式指定符:
1 | printf("%s\n", greeting); |
使用 scanf 函数读取字符串(注意,scanf在读取字符串时会因空格、制表符或换行符而停止读取):
1 | int var; |
字符串操作函数
C 标准库(string.h)提供了一系列操作字符串的函数,包括字符串连接、复制、长度计算等。
字符串复制
- strcpy(destination, source):复制source字符串到destination。
- strncpy(destination, source, n):复制最多n个字符从source到destination。
字符串连接
- strcat(destination, source):将source字符串追加到destination字符串的末尾。
- strncat(destination, source, n):将最多n个字符从source字符串追加到destination字符串的末尾。
字符串比较
- strcmp(str1, str2):比较两个字符串。如果str1与str2相同,返回
0。 - strncmp(str1, str2, n):比较两个字符串的前n个字符。
字符串长度
- strlen(str):返回str的长度,不包括结尾的
\0。
字符串查找
- strchr(str, c):查找字符c在str中首次出现的位置。
- strrchr(str, c):查找字符c在str中最后一次出现的位置。
- strstr(haystack, needle):查找字符串needle在haystack中首次出现的位置。
- strspn(str1, str2):返回str1中包含的仅由str2中字符组成的最长子串的长度。
- strcspn(str1, str2):返回str1中不含有str2中任何字符的最长子串的长度。
- strpbrk(str1, str2):搜索str1中的任何字符是否在str2中出现,返回第一个匹配字符的位置。
其他
- strdup(str):复制str字符串,使用malloc动态分配内存(非标准函数,但常见)。
- memset(ptr, value, num):将ptr开始的前num个字节都用value填充。
- memcpy(destination, source, num):从source复制num个字节到destination。
- memmove(destination, source, num):与memcpy相似,但正确处理重叠的内存区域。
下面是一个简单的示例,展示如何使用部分字符串函数:
1 |
|
函数
函数是一种让程序结构化的重要方式,允许代码的重用、模块化设计和简化复杂问题。
C 语言支持自定义函数和标准库函数。
函数定义与声明:
定义指明了函数的实际代码体(即函数做什么和如何做)。
声明告诉编译器函数的名称、返回类型和参数(类型和数量),但不定义具体的操作。
示例:
1 | /* |
函数参数传递
- 按值传递:函数收到参数值的副本。在函数内部对参数的修改不会影响原始数据。
- 按指针(地址)传递:通过传递参数的地址(使用指针),函数内的变化可以影响原始数据。
1 | // 按值传递 |
函数调用:
函数调用是 C 语言中一个核心概念,它允许在程序的任何地方执行一个函数。函数调用的基本过程包括将控制权从调用函数(caller)转移到被调用函数(callee),执行被调用函数的代码体,然后返回控制权给调用函数。
函数调用过程:
1. 参数传递:当调用函数时,会按照函数定义的参数列表,将实际参数的值(按值传递)或地址(按指针传递)传递给函数。
2. 执行函数体:一旦参数被传递,控制权转移到被调用函数,开始执行函数体内的代码。
3. 返回值:函数完成其任务后,可以通过 return 语句返回一个值给调用者。如果函数类型为 void,则不返回任何值。
4. 控制权返回:函数执行完毕后,控制权返回到调用函数的位置,程序继续执行下一条语句。
递归函数
递归函数是一种直接或间接调用自身的函数。它通常用于解决可以分解为相似子问题的问题。
示例:计算阶乘:n!
1 | int factorial(int n) { |
使用场景:递归在算法领域非常有用,尤其适合处理分治法、快速排序、二叉树遍历等问题。
内联函数
使用 inline 关键字声明的函数,在编译时会将函数体的代码直接插入每个调用点,而不是进行常规的函数调用。这可以减少函数调用的开销,但增加了编译后的代码大小。
示例:
1 | inline int max(int x, int y) { |
使用场景:对于那些体积小、调用频繁的函数,使用inline可以减少函数调用的开销,如简单的数学运算和逻辑判断函数。
回调函数
函数指针使得 C 语言支持回调函数,即将函数作为参数传递给另一个函数。
1 | void greet() { |
使用场景:
允许库或框架的用户提供自定义代码片段,根据需要在框架内部调用,以实现特定功能。例如,自定义排序函数中的比较操作。
函数的分类:
用户定义函数:由程序员定义的函数,用于执行特定任务。
标准库函数:C 语言标准库提供的函数,常见的标准库函数包括以下几类:
1. 输入和输出(stdio.h):用于格式化输入和输出,如printf和scanf,以及文件操作的fgets和fputs。
2. 字符串处理(string.h):提供字符串操作的基本函数,包括复制(strcpy)、连接(strcat)、长度计算(strlen)和比较(strcmp)。
3. 数学计算(math.h):包括幂函数(pow)、平方根(sqrt)和三角函数(sin, cos, tan)等数学运算。
4. 内存管理(stdlib.h):用于动态内存分配和释放,包括malloc、free和realloc等函数。
内存管理
在 C 语言中,内存管理是一个核心概念,涉及到动态内存分配、使用和释放。理解如何在C语言中管理内存对于编写高效、可靠的程序至关重要。
基本概念
C语言中的内存大致可以分为两大部分:静态/自动内存分配和动态内存分配。
静态内存分配:
静态内存分配发生在程序编译时,它为全局变量和静态变量分配固定大小的内存。这些变量在程序启动时被创建,在程序结束时才被销毁。例如,全局变量、static 静态变量都属于这一类。它的生命周期贯穿整个程序执行过程。
自动内存分配:
自动内存分配是指在函数调用时为其局部变量分配栈上的内存。这些局部变量只在函数执行期间存在,函数返回时它们的内存自动被释放。自动内存分配的变量的生命周期仅限于它们所在的函数调用栈帧内。
简而言之,静态内存分配涉及到整个程序运行期间都存在的变量,而自动内存分配涉及到只在特定函数调用期间存在的局部变量。
动态内存分配:
C语言中的动态内存分配是一种在程序运行时(而不是在编译时)分配和释放内存的机制。这允许程序根据需要分配任意大小的内存块,使得内存使用更加灵活。C 提供了几个标准库函数来管理动态内存,主要包括malloc、calloc、realloc和free。
下面让我们来看下这几个内存分配函数如何使用?
malloc :
malloc函数用来分配一块指定大小的内存区域。分配的内存未初始化,可能包含任意数据。
1 | /* |
释放内存
使用 free 函数来释放之前通过malloc、calloc或realloc分配的内存。释放后的内存不能再被访问,否则会导致未定义行为(如程序崩溃)。
释放内存后,已释放内存的指针称为悬挂指针。尝试访问已释放的内存将导致未定义行为。为了避免这种情况,释放内存后应将指针设置为 NULL。
1 | free(ptr); |
内存泄漏
如果忘记释放已分配的动态内存,这部分内存将无法被再次利用,导致内存泄漏。长时间运行的程序如果频繁泄漏内存,可能会耗尽系统资源。
检测和避免
检测工具:
- Valgrind:Linux下一个广泛使用的内存调试工具,可以帮助开发者发现内存泄漏、使用未初始化的内存、访问已释放的内存等问题。
- Visual Leak Detector (VLD):专为 Windows 平台开发的内存泄露检测工具,集成于Visual Studio,用于检测基于C/C++的应用程序。
避免策略:
及时释放内存:确保每次malloc或calloc后,相应的内存不再需要时使用 free 释放。
预处理指令
C 语言中的预处理指令是在编译之前由预处理器执行的指令。它们不是 C 语言的一部分,而是在编译过程中的一个步骤,用于文本替换、条件编译等。预处理指令以井号(#)开头。
下面是一些常见的预处理指令及其使用示例:
#include 指令
#include指令用于包含一个源代码文件或标准库头文件。它告诉预处理器在实际编译之前,将指定的文件内容插入当前位置。
1 |
#define 指令
#define用于定义宏。它告诉预处理器,将后续代码中所有的宏名称替换为定义的内容。
1 |
#undef 指令
#undef 用于取消宏的定义。
1 |
#if, #else, #elif, #endif 指令
这些指令用于条件编译。只有当给定的条件为真时,编译器才会编译这部分代码。
1 |
|
#ifdef 和 #ifndef 指令
#ifdef检查一个宏是否被定义,#ifndef检查一个宏是否未被定义。
1 | // 定义宏 DEBUG |
#error 和 #pragma 指令
#error 指令允许程序员在代码中插入一个编译时错误。当预处理器遇到#error指令时,它会停止编译过程,并显示紧跟在#error后面的文本消息。这对于指出代码中的问题、配置错误或不支持的编译环境非常有用。
1 |
_WIN64和__x86_64__是预定义的宏,它们通常在编译器层面被定义,用于指示特定的平台或架构。
这些宏不是在用户的源代码中定义的,而是由编译器根据目标编译平台自动定义。
#pragma 指令用于提供编译器特定的指令,其行为依赖于使用的编译器。它通常用于控制编译器的特定行为,如禁用警告、优化设置或其他编译器特定的特性。
1 |
下面是一个简单的示例,展示了如何使用预处理指令来控制代码的编译。
1 |
|
在这个示例中,如果DEBUG被定义,则程序会打印调试信息。这是通过条件编译指令#ifdef实现的。
C 语言的预处理指令是编写灵活和高效代码的强大工具。通过合理使用预处理指令,可以实现条件编译、调试开关等功能,从而提升代码的可维护性和性能。
输入和输出
在C语言中,输入和输出(I/O)是基于数据流的概念。数据流可以是输入流或输出流,用于从源(如键盘、文件)读取数据或向目标(如屏幕、文件)写入数据。C标准库stdio.h提供了丰富的I/O处理函数。
基础概念
数据流
1. 输入流:数据从输入源(如键盘、文件)流向程序。
2. 输出流:数据从程序流向输出目标(如显示器、文件)。
3. 标准流
- stdin:标准输入流,通常对应于键盘输入。
- stdout:标准输出流,通常对应于屏幕输出。
- stderr:标准错误流,用于输出错误消息,即使在标准输出被重定向的情况下,错误信息通常也会显示在屏幕上。
4. 文件流
除了标准的输入和输出流,C语言允许操作文件流,即直接从文件读取数据或向文件写入数据。
缓冲区
缓冲区是临时存储数据的内存区域,在数据在源和目标之间传输时使用。
分类:
- 全缓冲:当缓冲区满时,数据才会被实际地写入目的地。例如,向文件写入数据通常是全缓冲的。
- 行缓冲:当遇到换行符时,数据才会被实际地写入目的地。例如,标准输出stdout(通常是终端或屏幕)就是行缓冲的。
- 无缓冲:数据立即被写入目的地,不经过缓冲区。例如,标准错误 stderr 通常是无缓冲的
格式化输入、输出函数
scanf和printf:
printf 函数用于向标准输出(通常是屏幕)打印格式化的字符串。
scanf 函数用于从标准输入(通常是键盘)读取格式化的输入。
1 | int age; |
getchar和putchar: 字符输入、输出
getchar 函数用于读取下一个可用的字符从标准输入,并返回它。
putchar 函数用于写一个字符到标准输出。
1 | char ch; |
gets和puts : 字符串输入、输出
gets 函数用于从标准输入读取一行字符串直到遇到换行符。gets函数已经被废弃,因为它存在缓冲区溢出的风险,推荐使用fgets。
puts 函数用于输出一个字符串到标准输出,并在末尾自动添加换行符。
1 | char str[100]; |
文件操作
fopen、fclose、fgetc、fputc、fscanf、fprintf、feof、fseek、ftell、rewind
fopen 和 fclose 函数用于打开和关闭文件。
fgetc 和 fputc 用于读写单个字符到文件。
fscanf 和 fprintf 用于读写格式化的数据到文件。
feof 用于检测文件结束。
fseek 设置文件位置指针到指定位置。
ftell 返回当前文件位置。
rewind 重置文件位置指针到文件开始。
1 | FILE *file = fopen("example.txt", "w"); |
错误处理: perror
perror 函数用于打印一个错误消息到标准错误。它将根据全局变量 errno 的值输出一个描述当前错误的字符串。
1 | FILE *file = fopen("nonexistent.txt", "r"); |
标准库
C语言的标准库提供了一系列广泛使用的函数,使得处理输入输出、字符串操作、内存管理、数学计算和时间操作等任务变得简单。下面是一些基本的标准库及其常用函数的简单介绍:
stdio.h
用途:输入和输出
常用函数:printf()(输出格式化文本),scanf()(输入格式化文本)
stdlib.h
用途:通用工具,如内存管理、程序控制
常用函数:malloc()(分配内存),free()(释放内存),atoi()(字符串转整数)
string.h
用途:字符串处理
常用函数:strcpy()(复制字符串),strlen()(计算字符串长度)
math.h
用途:数学计算
常用函数:pow()(幂运算),sqrt()(平方根)
time.h
用途:时间和日期处理
常用函数:time()(获取当前时间),localtime()(转换为本地时间)
其他
typedef
typedef 是一种关键字,用于为现有的数据类型创建一个新的名称(别名)。这在提高代码的可读性和简化复杂类型定义方面非常有用。
用途:
- 定义复杂的数据结构:当你有一个复杂的结构体或联合体时,可以使用 typedef 给它一个更简单的名字。
- 提高代码的可移植性:通过 typedef 定义平台相关的类型,使得代码更容易在不同平台间移植。
示例
1 | typedef unsigned long ulong; |
在这个例子中,ulong 现在可以用作 unsigned long 类型的别名,而 Point 可以用作上述结构体的类型名称。
命令行参数
命令行参数允许用户在程序启动时向程序传递信息。C 程序的 main 函数可以接受命令行参数,这是通过 main 函数的参数实现的:int argc, char *argv[]。
用途
- 参数个数(argc):表示传递给程序的命令行参数的数量。
- 参数值(argv):是一个指针数组,每个元素指向一个参数的字符串表示。
示例:
1 |
|
在这个示例中,程序首先打印出程序自己的名字(argv[0]),然后检查是否有其他命令行参数传递给程序,并打印它们。
总结
本篇文章主要是提供一个 C 语言入门的学习指南,帮助初学者快速入门 C 语言。
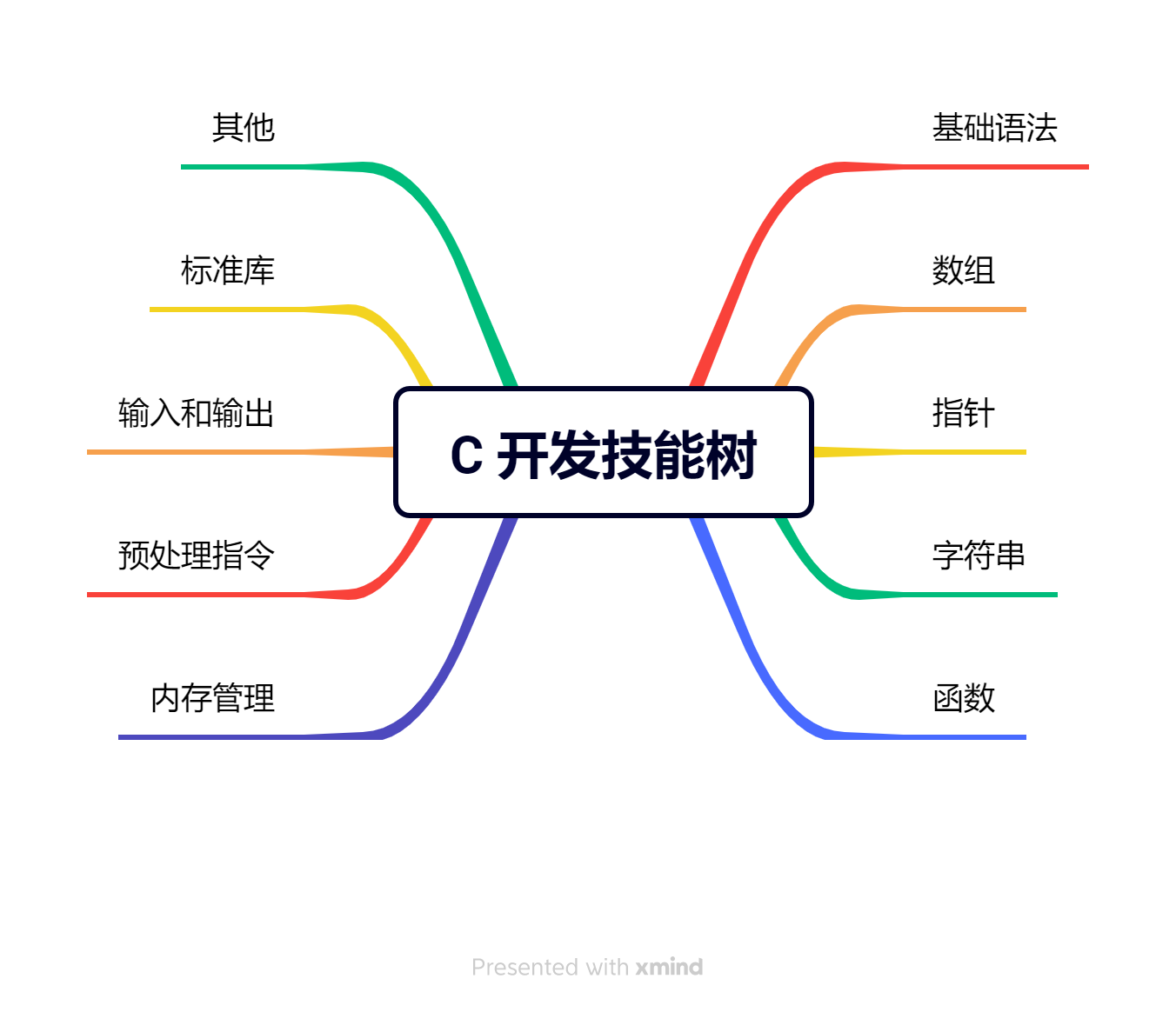
下面,让我们简短回顾下上文提到的知识点:
- 基础语法:我们介绍了 C 语言的基本构建块,包括变量声明、数据类型和控制流结构,这是编写任何 C 程序的基础。
- 数组和指针:这两个概念是 C 语言中管理数据集的核心工具。我们学习了如何通过它们高效地访问和操作数据。
- 字符串处理:学习了 C 语言中字符串的操作和处理方法,包括字符串的基本操作如连接、比较和搜索。
- 函数:介绍了函数的定义和使用,强调了封装和模块化代码的重要性,以提高程序的可读性和可维护性。
- 内存管理:了解了C语言如何与计算机内存直接交互,包括动态分配、使用和释放内存的方法。
- 预处理指令:讨论了预处理器如何在编译之前处理源代码,以及如何使用预处理指令来增强程序的可配置性和灵活性。
- 输入和输出:我们学习了标准输入输出库的基本使用,理解了如何实现程序与用户之间的交互。
- 标准库:介绍了C语言提供的强大标准库,它包括了一系列实用的函数和工具,用于处理字符串、数学计算、时间日期等。
最后:
当然,学习 C 语言只是学习编程的第一步,作为一门直接与硬件和操作系统打交道的计算机底层语言,要想掌握 C,你还得学习这两门课程:计算机组成原理、操作系统。甚至,你还得学习汇编语言。除此之外,学会在 Linux 环境下进行 C 编程也是必须要掌握的。 如果你想学习 Linux 编程,包括系统编程和网络编程相关的内容,可以关注我的公众号「跟着小康学编程」,这里会定时更新计算机编程相关的技术文章,感兴趣的读者可以关注一下:

另外,我最近新创建了一个技术交流群,大家如果在阅读的过程中有遇到问题或者有不理解的地方,欢迎大家加群询问或者评论区询问,我能解决的都尽可能给大家回复。微信扫下下方的二维码,备注「加群」即可。